목차
1. Loss Function
1.1 Multiclass SVM loss
1.2 Hinge loss
2. Regularization
2.1 L2 Regularization
2.2 L1 Regularization
3. Softmax Classifier (Multinomial Logistic Regression)
4. Softmax VS. SVM
5. Optimization
6. Gradient Descent
6.1 Stochastic Gradient Descent
7. Image Feature
7.1 Color Histogram
7.2 Histogram of Oriented Gradients
7.3 Bag of Words
1. Loss Function
Linear Classifier에서 이미지를 입력받으면 이미지를 열벡터로 변형 후 가중치 W와 연산하여
각 클래스별 score를 산출하고 이미지를 score가 가장 큰 클래스로 분류한다.
Loss Function이란 가중치 W가 이미지를 분류하는데 얼마나 좋은지 나쁜지를 정량적으로 수치화해주는 함수이다.
정확히는 얼마나 나쁜지에 대한 값이다.
L=1N∑Li(f(xi,W),yi)
- xi : input data
- yi : target data
- Li : i번째 데이터의 loss
1.1. Multiclass SVM loss
Multiclass SVM는 두개의 클래스가 아닌 여러 클래스를 다루기 위한 Binary SVM의 일반화된 형태이다.
Li=∑j≠yi{0 if syi⩾sj+1sj−syi+1 otherwise
- syi : True 클래스 score
- sj : False 클래스 score
Multiclass SVM loss를 구하기 위한 식은 위와 같고, Li를 구하는 과정을 보면 다음과 같다.
- True 클래스의 score가 False 클래스 score와 safety margin의 합보다 크면 loss는 0이 된다.
- 그렇지 않다면 (False 클래스 score) - (True 클래스 score) + (safety margin)이 해당 클래스의 loss가 된다.
- True 클래스를 제외한 나머지 class의 loss를 합하면 해당 데이터의 loss를 구할 수 있다.
그리고 전체 트레이닝 데이터 셋에서 loss들의 평균을 구하면 해당 데이터셋의 loss를 구할 수 있다.
safety margin : Multiclass SVM loss를 구하는 과정에서는 클래스 score의 정확한 값에는 관심이 없고 True 클래스와 False 클래스 score의 상대적인 차이에만 관심이 있다. 그래서 두 클래스의 차가 하이퍼 파라미터인 safety margin 값보다 크면 True 클래스의 score가 비교적 많이 크다고 판단하여 loss를 발생시키지 않는다.
W를 전체적으로 스케일링하면 결과 score도 이에 따라 스케일이 바뀌기 때문에 W의 스케일에 의해 상쇄됨
1.2 Hinge loss
또한, Multiclass SVM loss는 ∑j≠yimax(0,sj−syi+1)로도 나타낼 수 있고
0과 다른 값의 최대값과 같은 식으로 손실 함수를 만드는데
이런 손실 함수를 경첩과 닮았다 하여 hinge loss라고 부르기도 한다.

여기에서 x축은 syi이고 y축은 loss다.
True 클래스의 score가 올라갈수록 loss가 선형적으로 줄어들고 True 클래스와 False 클래스 score의 차가 safety margin을 넘어서면 loss가 0이 되는 것을 알 수 있다.
아래 그림은 CIFAR10 데이터셋을 활용하여 Multiclass SVM loss를 구하는 과정이다.
위 그림에서 첫 번쨰 사진의 True 클래스는 cat이기 때문에 False 클래스인 car와 frog를 순회한다.
cat과 car를 비교할 때 car의 score가 cat보다 더 높기 때문에 loss가 발생할 것이라는 것을 예상할 수 있디.
식을 통해 첫 번째 데이터의 loss는 2.9가 나오고 2.9는 분류기가 이 이미지를 얼마나 부정확하게 분류하는지에 대한 척도가 된다.
car와 frog 이미지에 대해서도 loss를 구하면 0과 12.9가 나오는데 각 이미지의 loss의 평균을 구하면 전체 데이터셋의 최종 loss를 구할 수 있다.
- Multiclass SVM loss : Example code
def L_i_Vectorized(x, y, W):
scores = W.dot(x)
margins = np.maximum(0, scores - scores[y] + 1)
margins[y] = 0
loss_i = np.sum(margins)
return loss_i
Question
1. car score가 조금 변하면 loss에는 무슨 일이 일어날까?
- 정답은 loss는 변하지 않고 계속 0일 것이다.
SVM loss에서는 score의 상대적인 차이만 고려하는데 car 클래스의 score는 다른 score들보다 많이 크기 때문에 score를 조금 바꾼다고 해서 loss는 변하지 않을 것이다.
2. SVM loss가 가질 수 있는 최대/최소값은 얼마일까?
- 최소값은 0, 최대값은 무한대
3. 파라미터를 초기화하고 처음부터 학습시킬때 W를 임의의 작은 수로 초기화시키는데, 모든 socre가 0에 가깝고 값이 서로 비슷하다면 loss가 어떻게 될까?
- 클래수의 수 - 1
syi와 sj가 0에 가깝고 비슷할 경우에 sj−syi+1 계산을 한다면 safety margin인 1만 남게 된다.
그러면 class 수에 따라 계산이 되는데 j≠yi이기 때문에 클래수의 수 -1 이 된다.
4. SVM loss 계산시 True 클래스의 score도 계산한다면 어떻게 될까?
- loss + 1
5. SVM loss 계산시 전체 합이 아닌 평균을 쓰면 어떻게 될까?
- 영향을 미치지 않는다.
score의 값이 중요한 것은 아니기 때문에 loss function을 rescale할 뿐이다.
6. loss function으로 ∑j≠yimax(0,sj−syi+1)2과 같이 제곱합을 한다면 어떻게 될까?
- 결과는 달라진다.
잘 예측한 것과 잘 예측하지 못한 것의 관계를 비선형적으로 바꾸기 때문
2. Regularization
만약 loss를 0으로 만드는 가중치 W를 찾았다고 하자.
그럼 W를 train data에 완벽하게 분류할 수 있다. 하지만 우리가 관심이 있는 것은 새로운 데이터에 대한 정확한 예측이다.
즉 아래 그림처럼 train data는 완벽하게 분류하지만 새로운 데이터에 대해서는 낮은 정확도를 보여주는 과적합이 발생할 수 있다.

이러한 문제를 해결하는 방법을 통틀어 Regularization을 한다.
이 방법은 보통 loss function에 Regularization term을 추가해 모델이 트레이닝 데이터셋에 완벽히 fit하지 못하도록 모델의 복잡도에 패널티를 부여하여 좀 더 단순한 W를 선택하도록 도와준다.
lambda : 규제의 강도를 나타내는 하이퍼 파라미터로 lambda 값이 높으면 모델이 단순해져 underfitting 위험이 생기고 값이 낮으면 모델이 복잡해져 overfitting 위험이 생긴다. R(W)와 trade off 관계를 가짐
2.1 L2 Regularization
가장 보편적인 Regularization 방법으로 Weight decay라고도 한다.
R(W)=∑k∑lW2k,l
W의 값을 제곱한 값을 모두 더한 뒤 loss function에 추가한다.
L=1N∑iLi+λ2n∑iw2
- W의 크기가 직접적인 영향을 끼침
- W 값을 0에 가깝도록 유도
- 모든 데이터 값의 input feature들을 고려함
- Ridge Regression
2.2 L1 Regularization
R(W)=∑k∑l|Wk,l|
W의 값에 절대값을 모두 더한 뒤 loss function에 추가한다.
L=1N∑iLi+λ2n∑i|w|
- W 업데이트 시 W의 크기에 관계없이 상수값을 빼게 되므로 작은 W들은 0으로 수렴
- 몇 개의 의미있는 값을 산출하고 싶은 sparse model 같은 경우 효과적
- 미분 불가능한 지점이 있기 때문에 gradient-base learning에서는 주의 필요
- Lasso Regression
3. Softmax Classifier (Multinomial Logistic Regression)
Multiclass SVM애서는 score 자체에 대한 해석은 고려하지 않았다.
하지만 Softmax Classifier의 loss function은 score 자체에 추가적인 의미를 부여한다.

다음과 같은 softmax라고 불리는 함수를 사용한다.
P(Y=k|X=xi)=esk∑jesj
계산 과정은 다음과 같다.
- 모든 score에 지수를 취해서 양수가 되게 만든다.
- 지수들의 합으로 정규화 시킨다.
- softmax 함수를 거친 후 나온 확률 분포가 해당 클래스일 확률을 나타낸다.
loss 다음과 같이 softmax를 거치고 나온 확률 값에 -log를 취해주면 된다.
Li=−log(esk∑jesj)

softmax는 True 클래스의 확률을 1로 만드는 것을 목표로 하고,
이러한 과정을 softmax 또는 Multinomial Logistic Regression이라 한다.
Question
1. Softmax loss의 최대값/최소값은 얼마일까?
- 최소값은 0, 최대값은 무한대
정답 클래스에 대한 log 확률이기 때문에 log(1)=0, -log(1)=0
2. 만약 score가 0 근처에 모여있는 작은 수일때 loss는 어떻게 될까?
- log(C)가 된다.
4. Softmax VS. SVM
두 loss function은 클래스 score에 대한 해석에 차이가 있다.
SVM에서는 클래스 score의 수치보다는 True 클래스와 False 클래스 score의 상대적인 차이에 관심을 가진다.
하지만 softmax는 해당 클래스일 확률을 구하고 True 클래스의 확률을 1로 만드는 것에 관심을 가진다.

SVM에서 car score가 다른 클래스의 score보다 많이 크기 때문에 car score를 조금 변화시켜도 loss는 변함이 없었지만 softmax에서는 1의 확률을 얻으려 할 것이므로 loss의 변화가 생길 것이다.
5. Optimization
우리는 Loss가 최소가 되는 W의 값을 찾아야 한다.
여기에는 여러가지 방법이 있다.
첫번째 생각해 볼 수 있는 방법으로는, 임의의 여러가지 W를 생성하여 그 중 Loss가 최소가 되는 지점의 W를 선택하는것이다.

하지만 이 방법은 정확률도 낮을뿐더러 시간도 오래걸린다.
두 번째 방법으로는 기울기를 사용하여 점진적으로 W를 업데이트 하는 것이다.

우리가 다루는 데이터는 다변량 함수이므로 gradient 벡터는 각 요소의 편도함수가 되게 된다. 이때, gradient의 방향은 함수에서 "가장 많이 올라가는 방향"이 되게 된다. 이를 마이너스를 붙이게 되면 반대로 "가장 많이 내려가는 방향"이 된다.
이제 유한 차분법을 이용하여 W의 기울기인 dW를 구해보려고 한다.

각 W의 요소에 아주 작은값의 h를 더한 후, loss fuction을 이용하여 loss를 구한다. 그 후, 미분의 정의를 이용하여 두 loss의 합의 차를 h로 나누어주게 되면 gradient dW를 구할 수 있게 된다.
하지만 이 방법으로는 시간이 굉장히 오래걸리기 때문에 실제로는 이 방식을 사용하지 않는다.

우리는 Loss function의 식을 정의하고 그 식을 미분하므로써 W를 구할 것이다.
그렇게 되면 시간 단축이 많이 된다.

위와 같이 미분 한번으로 gradient dW를 구할 수 있다.
6. Gradient Descent

(Gradient Descent) 경사하강법은 위의 3줄의 코드로 설명 가능하다. 먼저,W를 미분하여 gradient dW를 구하고 이 값에 step_size를 곱한만큼 W를 하강시킨다.
여기서 step_size는 learning rate라는 중요한 하이퍼파라미터로써 -gradient방향으로 얼마나 나아가야할지 알려주는 파라미터이다. 본 강의에서 강사는 이 파라미터를 무엇보다 먼저 정해준다고 한다. (가장 중요한 파라미터)
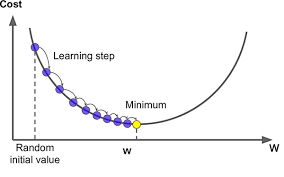
6.1 Stochastic Gradient Descent

Stochastic Gradient Descent는 전체 데이터를 미니배치(minibatch)로 나누어서 W를 업데이트 하는 방식이다.
미니 배치 사이즈는 보통 2의 배수인 32/64/128 등을 사용하고 이를 미니배치로 나누어서 학습시키는 이유는 데이터가 수십, 수백만개일 경우에는 W를 한번 학습하는데 굉장히 오랜 시간이 걸리게 되므로 이를 작은 데이터로 나누어서 학습시켜서 시간 단축을 하기 위해서이다.
7. Image Feature
실제 이미지의 raw 픽셀 값을 이용하여 모델을 학습시키는 방식은 좋지 않다. 따라서 우리는 Image에서 여러가지 Feature을 추출할 필요가 있다.

DNN(Deep Neural Network)이 유행하기 전에는 위와같이 두 개의 단계를 거치는 방법을 주로 사용했다.
첫 번째로, 이미지가 있으면 여러가지 특징 표현을 계산한다. 이런 특징 표현들은 이미지의 모양새와 관련된 것일 수 있다.
두 번째로, 여러 특징 표현들을 한데 연결시켜(Concat) 하나의 특징벡터로 만든다.
그 후, 이 특징벡터가 Linear Classifier의 입력으로 들어가게 된다.
이미지의 특징을 찾으려고 한 동기는 다음과 같다.

좌측의 좌표계의 데이터는 선형 분류가 불가능하다. 하지만 우측처럼 극좌표계로 변환하게 되면 쉽게 선형으로 두 데이터를 분류할 수 있게 된다.
위의 예시처럼 원래의 이미지 데이터(raw)를 가지고 모델을 학습시키는 것 보다 위와 같은 특징 변환을 거치면 모델의 성능이 더 향상될 수 있음을 알 수 있다.
다음으로는 특징 변환의 예들을 알아보자.
7.1 Color Histogram

첫 번째 특징변환의 예인 Color Histogram은 이미지의 Hue 값만 뽑아서 모든 픽셀을 각 양동이에 넣는 것이다.
그렇게 된다면 각 양동이에 담긴 픽셀 값의 개수를 알 수 있다.
이를 통해 우리는 이미지의 전체적인 색상을 알 수 있다.
7.2 Histogram of Oriented Gradients

두 번째 특징변환의 예는 Histogram of Oriented Gradients이다.
이미지가 있으면 먼저 8 X 8 픽셀로 나눈다. 그리고 이 8X8 픽셀 내부에서 가장 지배적인 Edge의 방향을 계산하고
이 방향을 양자화해서 각 양동이에 넣는다.
이러한 방식으로 edge orientations에 대한 히스토그램을 그리게 된다.
따라서 HoG는 이미지 내에 전반적으로 어떤 종류의 edge정보가 있는지 나타내게 된다.
HoG는 영상인식에서 정말 많이 활용한 특징벡터이다.
7.3 Bag of Words

세 번째 특징 변환의 예는 Bag of Words이다.
이는 NLP에서 영감을 받은것이다. 문장이 있을 때, bow에 여러 단어의 발생빈도를 세서 특징벡터로 활용하는 방식이다.
엄청 많은 이미지를 가지고, 그 이미지들을 임의로 조각낸다. 그리고 그 조각들을 k-means와 같은 방법으로 군집화한다. 이를 통해 이미지내의 다양한것을 표현할 수 있는 다양한 군집들을 만들어 내게 된다.
군집화 단계를 거치고나면 시각 단어(visual word)는 빨간색, 파란색, 노란색과 같은 다양한 색을 포착하게된다. 뿐만 아니라 다양한 종류, 방향의 oriented edge도 포착할 수 있다.
이런 시각 단어의 집합인 codebook을 만들고 나면 어떤 이미지에서 시각 단어들의 발생빈도를 통해 이미지를 인코딩 할 수 있다. 그리고 이 정보는 이미지가 어떻게 생겼는지에 대한 다양한 정보를 제공하게 된다.
Reference
CS231n 최신 강의 노트 (한글판) : http://aikorea.org/cs231n/classification/
https://process-mining.tistory.com/131

Kovi는 SSDC(Samsung Software Developer Community)를 기반으로 만들어진 커뮤니티입니다. ML, DL, Computer Vision, Robotics에 관심 있고 열정 있는 사람들이 모여 함께 활동 중입니다.
Kovi Instagram : https://www.instagram.com/kovi.or.kr/
Kovi SSDC : https://software.devcommunities.net/community/communityDetail/98
이 포스팅은 Kovi 커뮤니티 스터디의 일환으로 작성되었습니다.
posted by. heeh & Panda99
'CS231n' 카테고리의 다른 글
| [CS231n] Lecture 7. Training Neural Networks II (0) | 2023.03.04 |
|---|---|
| [CS231n] Lecture 6. Training Neural Networks 1 (수정 중) (0) | 2023.03.02 |
| [CS231n] Lecture 5. CNN: Convolution to Neural Networks (2) | 2023.03.02 |
| [CS231n] Lecture 4. Backpropagation and Neural Networks (0) | 2023.02.14 |
| [CS231n] Lecture 2. Image Classification (0) | 2023.02.03 |