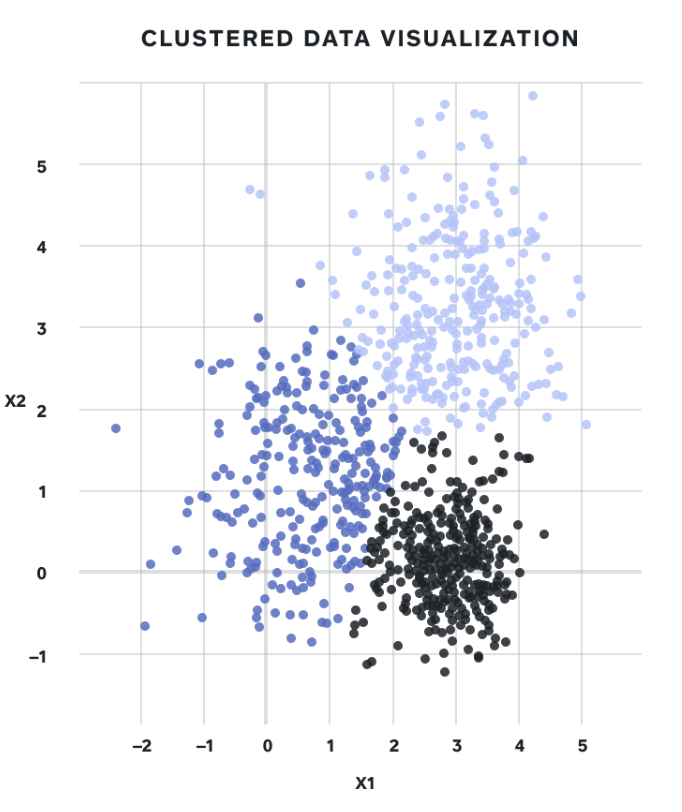
목차 1. 군집 (Clustering) 1.1 k-평균 1.2 k-평균의 한계 2. DBSCAN 2.1 DBSCAN 동작 원리 2.2 DBSCAN을 활용하여 새로운 샘플의 클러스터 예 3. 가우시안 분포 4. 가우시안 혼합 모델 (Gaussian mixture model) 이란? 4.1 가우시안 혼합 모델(GMM)의 그래프 모형 4.2 기댓값-최대화(EM) 알고리즘 4.2.1 초기화 4.2.2 기대값 단계 4.2.3 최대화 단계 4.2.4 EM 알고리즘 정리 4.3 이상치 탐지 4.4 클러스터 개수 선택하기 5. 베이즈 가우시안 혼합 모델(BayesianGaussianMixture model) 5.1 베이즈 가우시안 혼합 모델 모형 5.2 베이즈 정리 비지도 학습이란? 비지도 학습인 라벨링이 되어 있지 ..