목차
- 결정 트리란
- 결정 트리 학습과 시각화
- 클래스 확률 추청
- CART 훈련 알고리즘
- 계산 복잡도
- 지니 불순도 또는 엔트로피
- 규제 매개변수
- 회귀
- 불안정성
1. 결정 트리란
서보트벡터머신 (SVM)처럼 분류와 회귀 작업 그리고 다중출력 작업도 가능한 다재다능한 머신러닝 알고리즘
복잡한 데이터셋도 가능. 쉽게 말해 스무고개와 비슷한 원리이며 랜덤 포레스트의 기본 구성요소 이기도함
결정 트리는 직관적이고 결정 방식을 이해하기 쉬운 화이트박스 모델임
2. 결정트리(Decision Tree) 학습과 시각화
2.1 데이터 불러오기
import pandas as pd
from sklearn.datasets import load_iris
iris = load_iris()
df = pd.DataFrame(iris.data, columns = iris.features_names)
df["class"] = iris.target
df.head()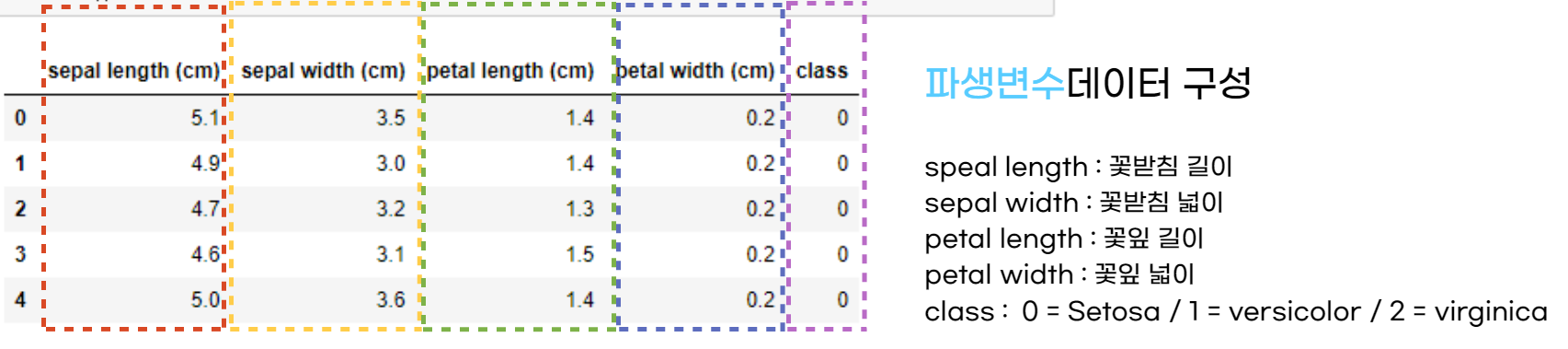
2.2 결정트리 학습 및 시각화
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import export_graphviz
from graphviz import source
X = df[:, 2:]
y = df["class"]
#모델 학습
tree_clf = DecisionTreeClassifier(max_depth = 2)
tree_clf.fit(X, y)
#export_graphviz()의 호출 결과를 tree.dot으로 저장
export_graphviz(tree_clf,
out_file = image_path = "tree.dot",
class_name = iris.target_names,
feature_names = iris.feature_names[2:],
rounded = True,
filled = True)
#tree.dot 불러오기
with open("tree.dot") as f:
dot_graph = f.read()
graphviz.Source(dot_graph)
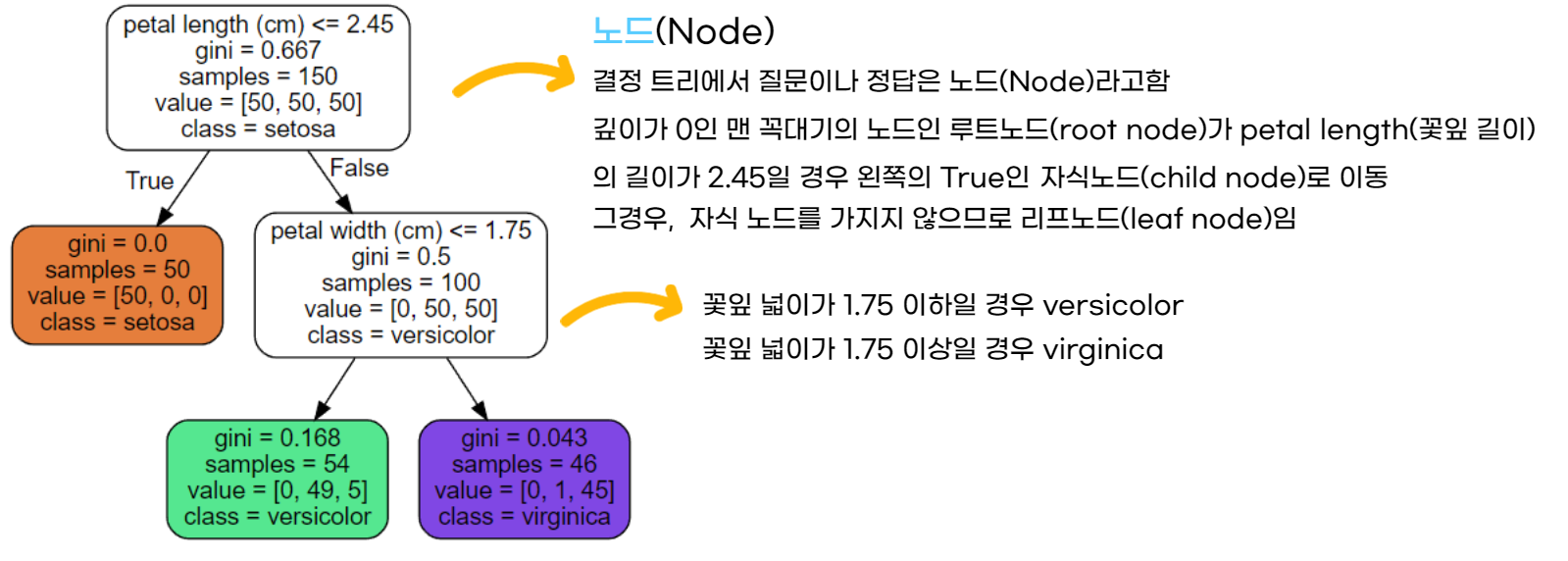
- samples : 얼마나 많은 훈련 데이터가 적용되었는지에 대한 개수
- value : 각 클래스별 개수, 현재 상태는 각 꽃 종류마다 50개씩 분포
- GINI 불순도 : 불순도(Impurity)란 해당 범주 안에 서로 다른 데이터가 얼마나 섞여있는지를 뜻하며, 의사결정 나무의 분리가 잘 된 것을 평가하기 위함 $$1 - \sum_{m}^{k=1}p^2_k$$ values = [0, 1, 45]에서 GINI 불순도 : $1-[(\frac{1}{46})^2 + (\frac{45}{46})^2]$ = 0.043
결정트리의 결정경계
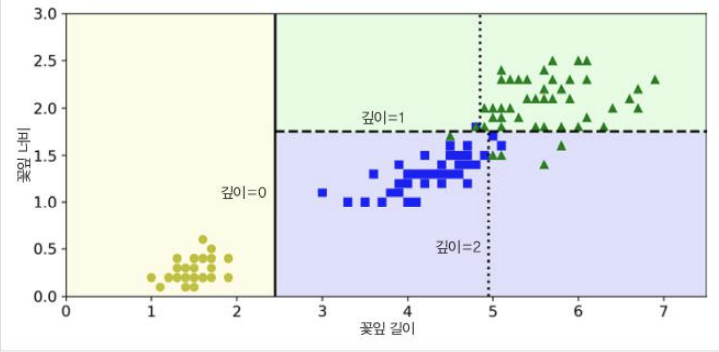
현재 max_depth = 2인 경우 이며 max_depth = 3일 경우 점선 경계 추가
3. 클래스 확률 추청
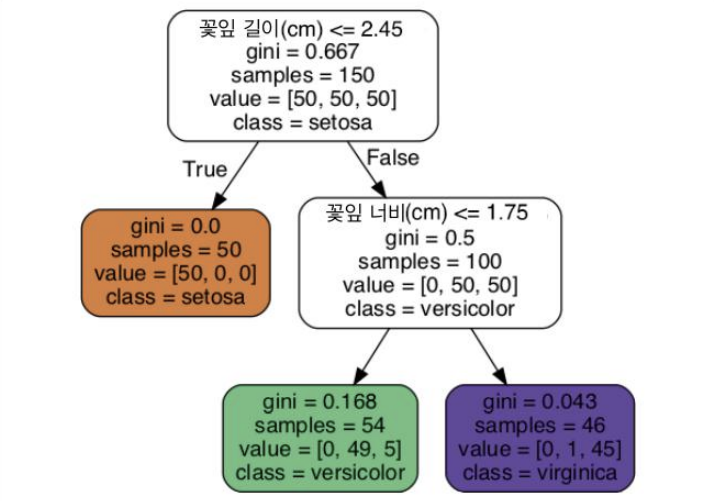
꽃잎의 길이가 5이고 너비가 1.5인 꽃을 발견 했을 경우
깊이가 2인 노드에서 왼쪽인 경우이므로 setosa일 확률 0/54, versicolor일 확률 49/54, virginica일 확률 5/54
하나의 클래스를 예측한다면 이 경우는 versicolor 출력
4. CART 훈련 알고리즘
CART(classification and regression tree)
먼저 크기에 따른 가중치가 적용된 가장 순수한 서브셋으로 나눌 수 있는 특성 k와 임계값 $T_k$를 찾는다
훈련 세트를(k,$T_k$) 사용해 두 개의 서브셋으로 나눈다
CART 알고리즘이 훈련 세트를 성공적으로 둘로 나누었다면 같은 방식으로 서브셋을 또 나누고 그 다음엔 서브셋의 서브셋을 나누고 이런 식으로 계속 반복하며 최대 깊이가 되면 중지하거나 불순도를 줄이는 분할을 찾을 수 없을 때 멈추게 된다
$$J(K,t_k) = \frac{m_{left}}{m}G_{left} + \frac{m_{right}}{m}G_{right}$$
- G : 불순도
- m : 샘플 수
CART 알고리즘은 탐욕적 알고리즘으로 여러 경우 중 하나를 결정해야 할 때마다 그 순간에 최적이라고 생각되는 것을 선택해 나가는 방식으로 진행하여 최종적인 해답에 도달한다
순간마다 하는 선택은 그 순간에 대해 최적이지만, 종합적으로 봤을 때 최적이라는 보장은 없다
5. 계산 복잡도
예측을 하려면 결정 트리를 root 노드에서부터 leaf 노드까지 탐색해야함
일반적으로 결정트리는 거의 균형을 이루고 있고 각 노드는 하나의 특성값만 확인하기 때문에
예측에 필요한 전체 복잡도는
$$O(Log_2{(m)})$$
을 따른다
- Big-O(빅 오) : 알고리즘 최악의 실행 시간을 표기함
연습문제 1 : 백만 개의 샘플을 가진 훈련 세트에서 (규제 없이) 훈련시킨 결정 트리의 깊이는 대략 얼마일까
$$Log_2{(10^6)} = \frac{Log_{10}{(10^6)}}{Log_{10}{(2)}} = 19.6... $$
6. 지니 불순도 또는 엔트로피
기본적으로 지니 불순도가 사용되지만 criterion 매개변수를 "entropy"로 지정하여 엔트로피 불순도를 사용할 수 있고
두 방법은 큰차이가 없으며 비슷한 트리를 만들어 냄
기본값으로는 계산이 빠를 지니 불순도를 쓰지만 지니 불순도는 가장 빈도 높은 클래스를 한쪽으로 고립시키는 경항이 있는 반면 엔트로피는 조금 더 균형 잡힌 트리를 만듬
$$H_i = -\sum_{k=1}^{n}p_{i,k}\;log_2{(p_{i,k})},\quad p_{i,k}\neq 0$$
- 엔트로피 : 열역학에서 주로 쓰이며 어느 정도로 구분되어 있는지, 구분이 되어 있지않은 무질서에 가까운지를 측정하는 척도
ex) values = [0, 1, 45]에서 엔트로피는
$$-\frac{1}{46}log_2{(\frac{1}{46})}-\frac{45}{46}log_2{(\frac{45}{46})} = 0.1510967051$$
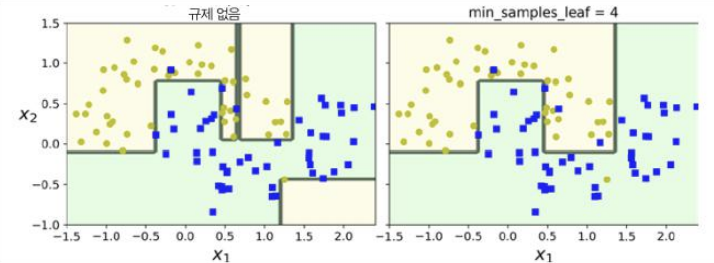
7. 규제 매개변수
훈련 데이터에 대한 과대적합을 피하기 위해 결정 트리의 자유도를 제한할 필요가 있음
sickit-learn에서는 max_depth 매개변수로 조절, max_depth를 줄이면 과대적합 위험 감소
DesicionTreeClassifier에는 비슷하게 트리의 형태를 제한하는 매개 변수가 몇개 있음
- min_samples_split : 분할하기 위해 노드가 가져야하는 최소 샘플 수
- min_samples_leaf : 리프 노드가 가지고 있어야 할 최소 샘플 수
- min_weight_fraction_leaf : min_samples_leaf와 같지만 가중치가 부여된 전체 샘플 수에서의 비율
- max_leaf_nodes : 리프 노드의 최대수
- max_features : 각 노드에서 분할에 사용할 특성 최대수
※ min으로 시작하는 매개변수 값을 증가시키거나 max로 시작하는 매개변수 값을 감소시키면 모델에 대한 규제가 커짐
8. 회귀
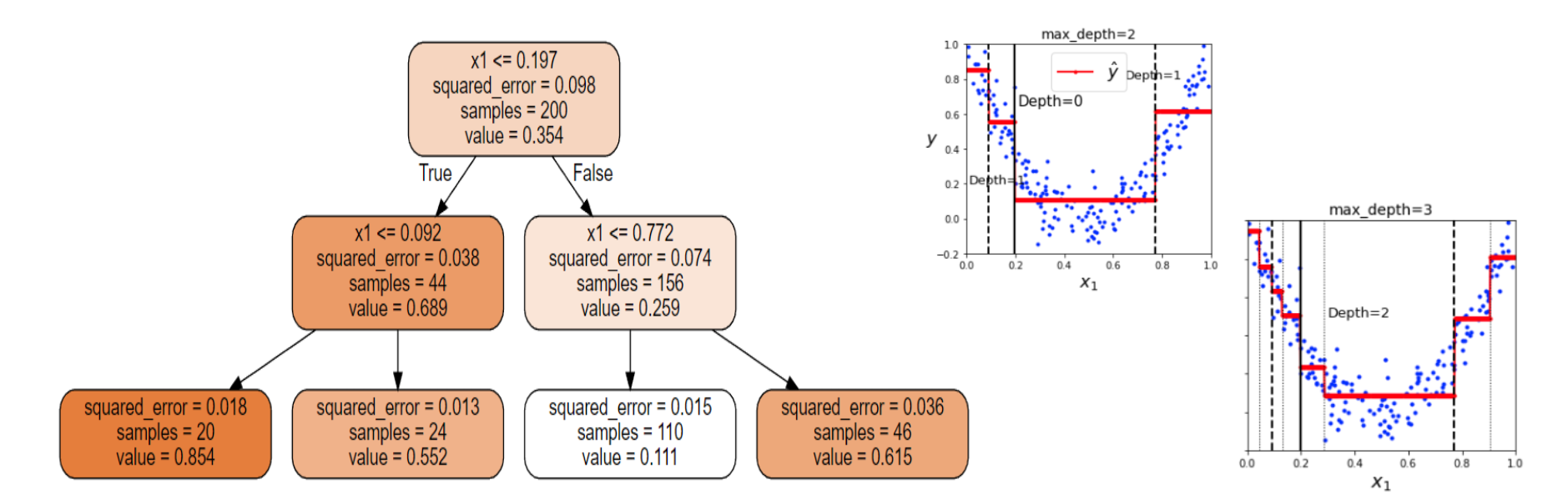
분류와 다르게 각 노드에서 어떤 값을 예측함
예를 들어 $x_1 = 0.6$인 샘플의 클래스를 예측하면 root노드에서 시작해서 트리를 순회하면 value = 0.111인 리프노드에 도달하게됨. 각 영역의 예측값은 항상 그 영역에 있는 타깃 값의 평균이 되며 알고리즘은 예측값과 가능한 많은 샘플을 가까이 있도록 영역을 분할함
CART 알고리즘은 분류모델에서 썼던 GINI 불순도 대신에 MSE(Mean Squared Error)를 사용하며 거의 비슷하게 작동함.
$$J(k,t_k) = \frac{m_{left}}{m}MSE_{left} + \frac{m_{right}}{m}MSE_{right}$$
9. 불안정성
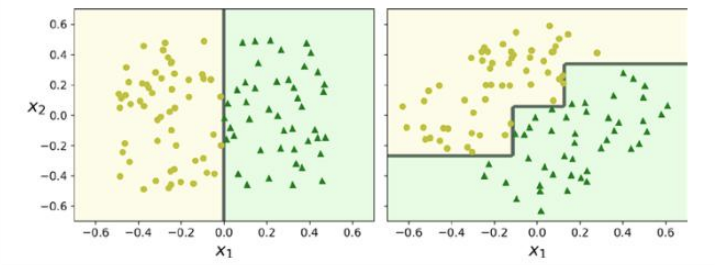
결정트리의 주된 문제는 훈련 데이터에 있는 작은 변화에도 매우 민감함
결정트리는 계단 모양의 결정 경계를 만듦으로 인해 모든 분할은 축에 수직이므로 같은 훈련 세트라도 회전에 민감하다.
문제를 해결하기 위한 한가지 방법으로는 PCA기법이 존재
- PCA(주성분 분석, Principal Component Analysis)
고차원의 데이터를 저차원의 데이터로 축소시키는 차원 축소 방법 중 하나

Kovi는 SSDC(Samsung Software Developer Community)를 기반으로 만들어진 커뮤니티입니다. ML, DL, Computer Vision, Robotics에 관심 있고 열정 있는 사람들이 모여 함께 활동 중입니다.
Kovi Instagram : https://www.instagram.com/kovi.or.kr/
Kovi SSDC : https://software.devcommunities.net/community/communityDetail/98
이 포스팅은 Kovi 커뮤니티 스터디의 일환으로 작성되었습니다.
posted by.
'Hands-On Machine Learning' 카테고리의 다른 글
| [핸즈온머신러닝] CH8. 차원 축소 (Dimension Reduction) (0) | 2023.01.13 |
|---|---|
| [핸즈온머신러닝] CH7. 앙상블(Ensemble) 학습 (0) | 2022.12.09 |
| [핸즈온머신러닝] CH5. 서포트 벡터 머신(Support Vector Machine; SVM) (0) | 2022.12.09 |
| [핸즈온머신러닝] CH4. 모델 훈련 (Training Model) (0) | 2022.11.27 |
| [핸즈온머신러닝] CH3. 분류 (Classification) (0) | 2022.11.27 |